
1) Understand what data we have to migrate
Clients will usually have one of the following:- A simple file structure containing assets in categories and sub-categories. Clients usually want us to then put these into Asset Bank, converting the folder structure into categories in Asset Bank.
- A simple file structure containing assets in categories and sub-categories that also have embedded metadata (data that is stored inside the actual files such as title or keywords). Clients will want us to convert these into categories in Asset Bank whilst extracting the metadata and putting this into relevant attributes so that this data is visible and searchable.
- A set of files and a corresponding spreadsheet that has been exported from their legacy system. The files usually have a unique filename that then corresponds to a row in the spreadsheet which itself holds the metadata for this file.
- Some other combination of the above (e.g. a file structure along with a metadata spreadsheet and some embedded metadata).
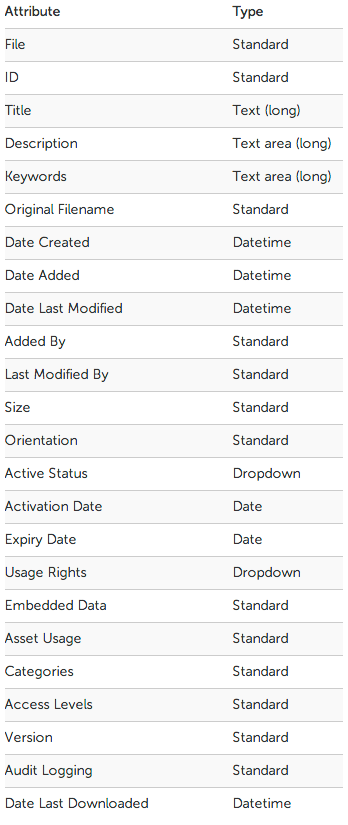
2) Set up any relevant attributes
If embedded metadata is to be extracted on upload, then we need to ensure corresponding attributes exist in Asset Bank to receive this data. The same is true if we are migrating data from a spreadsheet into Asset Bank.
When we set these up we also need to ensure that the type of each is correct. So for example, a text area for a description field, a drop-down for a country field, etc. These types may be inferred from the legacy system or we can work with the client to decide on what type is best for each field.
3) Set up any embedded data mappings
If there is any embedded metadata that is to be extracted, then we have to set up these extraction mappings in Asset Bank.
For example, we can set things up to say:
Map any embedded IPTC Keywords to the Asset Bank keyword attribute. Then on upload this information will be automatically pulled across into the relevant assets metadata.

Embedded metadata mappings can be configured
Read more about embedded data mappings.
4) Ingest the assets
To get the assets into Asset Bank they must first be moved onto the server where Asset Bank is installed. If you have the assets in a folder structure that you would like to convert to categories on ingest, then this whole structure can be moved onto the server. Asset Bank can then be configured to ingest these files, converting the folders and sub folders into categories in Asset Bank, and putting all of the content into the correct locations.
At the same Asset Bank will automatically generate web optimised previews of each asset including:
- thumbnail, medium and large image previews for all image assets (e.g. JPG, TIF, AI, PSD, etc.)
- video preview clips
- audio preview clips
- PDF and PowerPoint previews

If embedded metadata mappings where also set up then the relevant information will now also be visible on the details page for each asset.
5) Import any additional metadata (e.g. from spreadsheets)
Now that the assets are in the system we can complete the migration by ingesting and matching up any additional metadata that may exist, e.g. from a spreadsheet that has been exported from a legacy system (or one that has been created manually). The key to this step is ensuring there is a unique identifier that can be used to link the relevant metadata to the right asset. The unique identifier is usually the filename, but can be the filepath (as per the folder structure) and filename if the filename itself is not unique across the set of data.

The process is now complete. We offer this data migration service on a Time & Materials basis. Please contact us for more details.
Additional detailed information can be found here:


